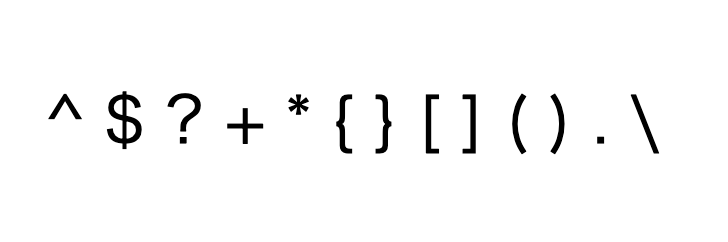
正規表現(Regular Expression、略してRegex)は、テキストのパターンを記述するための特殊な文字列です。主に文字列の検索、置換、抽出などの操作で使用されます。
正規表現は様々な文字や記号を組み合わせてパターンを定義します。例えば、特定の文字列を検索したり、文字列の形式やパターンに一致するものを抽出するために使われます。
一般的な正規表現のパターンには、以下のようなものがあります:
- 文字のマッチング: 文字をそのままマッチングする。例えば、
aは文字aに一致します。 - 特殊文字: 正規表現では、特殊な意味を持つ文字があります。
.(ピリオド)はどの1つの文字にもマッチするワイルドカード文字です。^は文字列の先頭、$は文字列の末尾を表します。 - 文字クラス:
[ ]内に文字や範囲を指定することで、それらの中のいずれか一文字とマッチングします。例えば、[abc]はaまたはbまたはcに一致します。 - 量指定子:
+,*,?などの量指定子は直前のパターンが何回出現するかを指定します。例えば、a+はaが1回以上続くものにマッチングします。 - グループ化とバックリファレンス:
( )を使用してパターンをグループ化し、後でそのグループ全体を参照できます。また、\1,\2のようにしてマッチングしたグループを後で再利用することができます。
正規表現は非常に強力で柔軟性がありますが、複雑なパターンを書く場合には読みやすさや理解しやすさが低下することがあります。正規表現を使う際には、パターンのテストやデバッグを行いながら少しずつ構築していくと良いでしょう。
多くのプログラミング言語やテキストエディタが正規表現をサポートしており、それぞれ微妙な違いはありますが、基本的な構文や機能は共通しています。