
emp表 ※indexはなし(primary keyのみ)
CREATE TABLE `emp` (
`id` int NOT NULL AUTO_INCREMENT,
`dept` int DEFAULT NULL,
`age` int DEFAULT NULL,
`sex` int DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`bikou` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`birth` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2490316 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ciレコードは100万件
※データの作成はこちらを参照
dept表 ※indexはなし(primary keyのみ)
CREATE TABLE `dept` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL,
`登録日` date NOT NULL,
PRIMARY KEY (`id`)
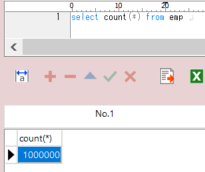
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ciレコードは10件
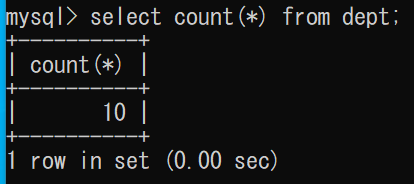
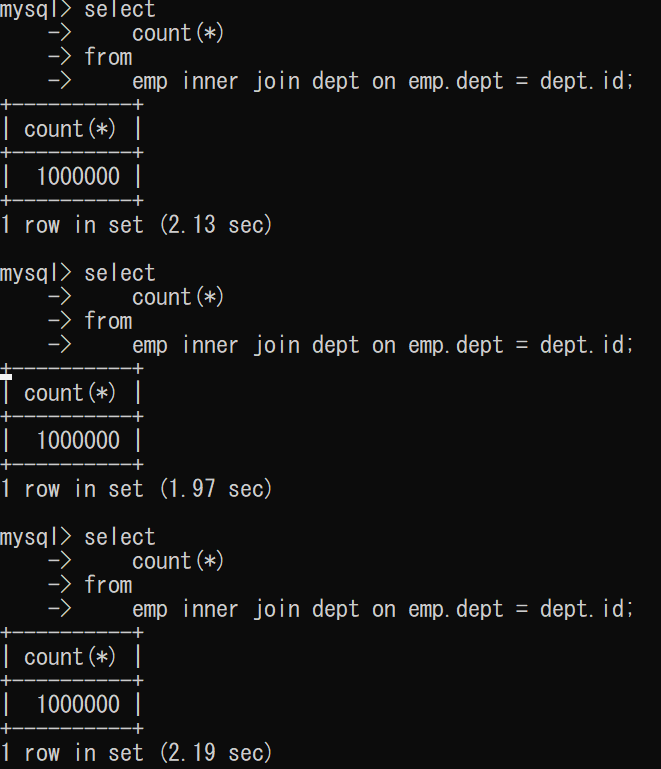
empテーブルとdeptテーブルを内部結合させる
このとき、empテーブルのdeptにはindexが作られていない。
結果は平均 2 secくらい。
ここでempテーブルのdeptにindexを作成。
create index idx_dept on emp(dept);CREATE TABLE `emp` (
`id` int NOT NULL AUTO_INCREMENT,
`dept` int DEFAULT NULL,
`age` int DEFAULT NULL,
`sex` int DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`bikou` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`birth` date DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_dept` (`dept`)
) ENGINE=InnoDB AUTO_INCREMENT=2490316 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci再実行してみます
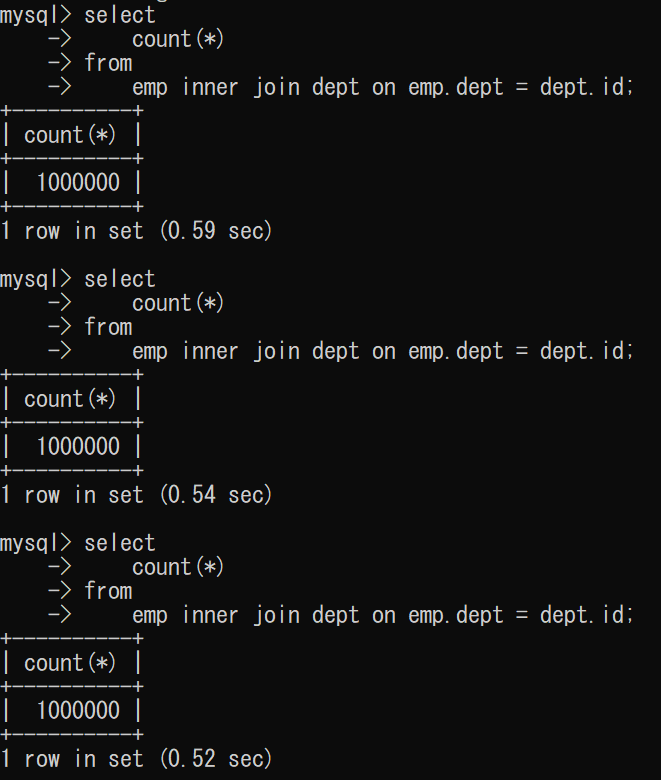
平均0.5 secと実行結果が速くなりましたね。
それでは各実行計画を比較してみる
indexなしの場合

EXPLAINの結果の各カラムの意味
- id: クエリの各部分に一意の識別子を割り当てます。このクエリは単一のSELECT文であるため、
1です。 - select_type: クエリのタイプを示します。
SIMPLEは、サブクエリを含まない単純なSELECT文であることを示します。 - table: クエリの対象となるテーブルを示します。ここでは
empとdeptの両方が表示されています。 - partitions: 使用されるパーティションを示します。ここでは
NULLで、パーティションは使用されていないことを示します。 - type: テーブルへのアクセス方法を示します。
ALLは全行スキャン(フルテーブルスキャン)が行われていることを示します(empテーブル)。eq_refは、結合で使用される主キーの一意インデックスを示します(deptテーブル)。
- possible_keys: クエリで使用可能なインデックスを示します。ここでは
NULLまたはPRIMARYが表示されています。 - key: 実際に使用されるインデックスを示します。
NULLは、empテーブルではインデックスが使用されていないことを示します。PRIMARYは、deptテーブルで主キーインデックスが使用されていることを示します。
- key_len: 使用されているインデックスキーの長さを示します。
PRIMARYキーの長さは4バイトです。 - ref: インデックスのカラムに一致する値を示します。
performance.emp.deptは、deptテーブルの主キーに対応するempテーブルのdeptカラムを示します。 - rows: MySQLがクエリ実行時に検査すると推定する行の数を示します。
empテーブルでは985,251行、deptテーブルでは1行です。 - filtered: 条件を満たすと予想される行の割合を示します。ここでは両テーブルとも
100.00%です。 - Extra: クエリの追加情報を示します。
Using whereは、empテーブルに対してWHERE句によるフィルタリングが行われていることを示します。Using indexは、deptテーブルに対してインデックスカバーが行われていることを示します。
解釈
この結果から、次のことがわかります:
- 全行スキャン(フルテーブルスキャン):
- typeが
ALLであるため、empテーブルの全行をスキャンしています。適切なインデックスがないため、全行をチェックする必要があります。
- typeが
- インデックス使用の違い:
deptテーブルでは、typeがeq_refで、主キーインデックスが使用されています。これは一意インデックスによる参照であり、効率的な結合が行われています。empテーブルではインデックスが使用されていません(keyがNULL)。
- インデックスの欠如:
- possible_keysが
NULLであるため、empテーブルには使用可能なインデックスがないことがわかります。
- possible_keysが
- 行数の推定:
- rowsが
985,251で、これはMySQLがempテーブルの全行をスキャンすると推定する行の数です。 deptテーブルでは、結合条件に基づいて1行のみが関連しています。
- rowsが
- フィルタリングの効率:
- filteredが
100.00で、empテーブルに対してWHERE句の条件が全行に適用されていることを示します。
- filteredが
- 追加のフィルタリング:
- Extraが
Using whereで、empテーブルに対してフィルタリングが行われていることを示します。 deptテーブルでは、ExtraがUsing indexであり、インデックスを使用して効率的にデータにアクセスしていることを示します。
- Extraが
続いてindexありの場合の実行計画

EXPLAINの結果の各カラムの意味
- id: クエリの各部分に一意の識別子を割り当てます。このクエリは単一のSELECT文であるため、
1です。 - select_type: クエリのタイプを示します。
SIMPLEは、サブクエリを含まない単純なSELECT文であることを示します。 - table: クエリの対象となるテーブルを示します。ここでは
deptとempの両方が表示されています。 - partitions: 使用されるパーティションを示します。ここでは
NULLで、パーティションは使用されていないことを示します。 - type: テーブルへのアクセス方法を示します。
indexはインデックススキャンが行われていることを示します(deptテーブル)。refはインデックスによる参照が行われていることを示します(empテーブル)。
- possible_keys: クエリで使用可能なインデックスを示します。ここでは
PRIMARYとidx_deptが表示されています。 - key: 実際に使用されるインデックスを示します。
PRIMARYはdeptテーブルの主キーインデックスを使用し、idx_deptはempテーブルのインデックスを使用しています。 - key_len: 使用されているインデックスキーの長さを示します。
PRIMARYキーの長さは4バイト、idx_deptの長さは5バイトです。 - ref: インデックスのカラムに一致する値を示します。
performance.dept.idはdeptテーブルの主キーに対応するempテーブルのdeptカラムを示します。 - rows: MySQLがクエリ実行時に検査すると推定する行の数を示します。
deptテーブルでは10行、empテーブルでは109,472行です。 - filtered: 条件を満たすと予想される行の割合を示します。ここでは両テーブルとも
100.00%です。 - Extra: クエリの追加情報を示します。
Using indexは、クエリがインデックスカバーされている(インデックスだけでクエリが完了する)ことを示します。
解釈
この結果から、次のことがわかります:
- インデックススキャンとインデックス参照:
- typeが
indexであるため、deptテーブルではインデックススキャンが行われています。これは、インデックスのみを使用してテーブル全体を走査することを示します。 - typeが
refであるため、empテーブルではインデックスによる参照が行われています。これは、特定の値(ここではdept.id)に基づいてインデックスが使用されていることを示します。
- typeが
- インデックスの使用:
deptテーブルではkeyがPRIMARYであり、主キーインデックスが使用されています。empテーブルではkeyがidx_deptであり、deptカラムのインデックスが使用されています。
- インデックスキーの長さ:
- key_lenが
PRIMARYインデックスの長さで4バイト、idx_deptインデックスの長さで5バイトです。
- key_lenが
- 行数の推定:
- rowsが
10で、deptテーブルの全行数が10であることを示します。 - rowsが
109,472で、これはMySQLがインデックスを使用して検索すると推定するempテーブルの行の数です。
- rowsが
- フィルタリングの効率:
- filteredが
100.00で、両テーブルのインデックスによる検索結果が条件を完全に満たしていることを示します。
- filteredが
- 追加のフィルタリングの欠如:
- Extraが
Using indexで、クエリがインデックスカバーされていることを示します。インデックスだけでクエリが完了するため、テーブルの行にアクセスする必要がありません。これによりパフォーマンスが向上します。
- Extraが